

The POCO C++ Libraries (POCO stands for “Portable Components”) is a collection of open-source C++ class libraries that simplify and accelerate the development of network-centric, portable applications in C++. These libraries provide a wealth of features, ranging from HTTP and HTTPS clients and servers, to XML parsing, to data encryption, to threading support, and much more.
We’ve relied on the POCO library for over 15 years to verify whether CppDepend accurately evaluates well-implemented projects. Therefore, this assessment is not drawn from a fleeting encounter with the library but from a thorough analysis of its many versions over the past 15 years.
Let’s explore a code snippet from the POCO source code: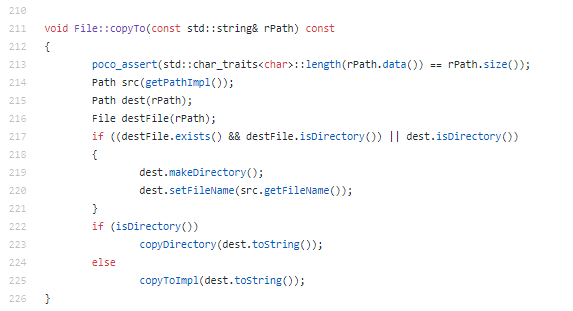
This method implementation is characterized by:
- Has a few parameters.
- Assert technique is used to check if the entries are OK.
- The variable names are easy to understand.
- The method is short.
- No extra comments in the body. The code explains itself.
- The function body is well indented.
- The STL library is used when needed.
When delving into the POCO source code, one can readily observe the consistency of its implementation, as the same best practice rules are applied to each function. Upon exploring the source code, it becomes apparent that POCO is approachable even for C++ beginners. Specifically, POCO has the following characteristics:
- It’s not over-engineered, and one doesn’t need to possess advanced C++ skills to comprehend its implementation.
- The public classes provided to end users are well-organized and straightforward to utilize.
- The design is modular, with the library divided into several projects, each addressing a specific need.
- For those seeking advanced utilization of the library, extending, customizing, or modifying the behavior of certain classes is remarkably straightforward.
In this post we will focus on some keys of its design:
ABSTRACT VS INSTABILITY
Robert C.Martin wrote an interesting article about a set of metrics that can be used to measure the quality of an object-oriented design in terms of the interdependence between the subsystems of that design.
Here’s from the article what he said about the interdependence between modules:
What is it that makes a design rigid, fragile and difficult to reuse. It is the interdependence of the subsystems within that design. A design is rigid if it cannot be easily changed. Such rigidity is due to the fact that a single change to heavily interdependent software begins a cascade of changes in dependent modules. When the extent of that cascade of change cannot be predicted by the designers or maintainers the impact of the change cannot be estimated. This makes the cost of the change impossible to estimate. Managers, faced with such unpredictability, become reluctant to authorize changes. Thus the design becomes rigid.
And to fight the rigidity he introduce metrics like Afferent coupling, Efferent coupling, Abstractness, Instability and the “distance from main sequence” and the “Abstractness vs Instability” graph.
The “Abstractness vs Instability” graph can be useful to identify the projects difficult to maintain and evolve. Here’s the “Abstractness vs Instability” graph of the POCO library:
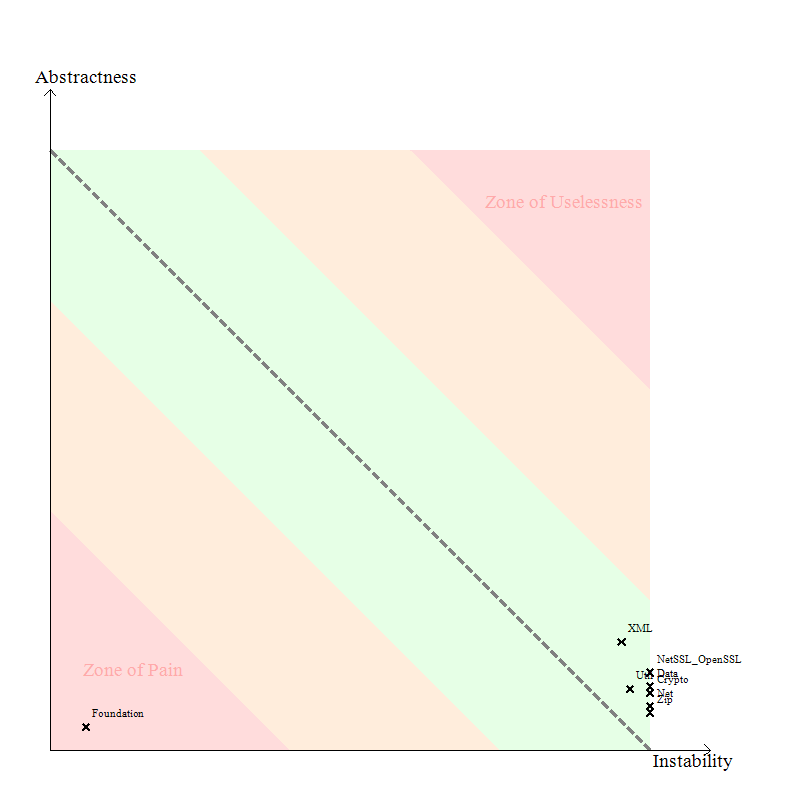
The idea behind this graph is that the more a code element of a program is popular, the more it should be abstract. Or in other words, avoid depending too much directly on implementations, depend on abstractions instead. By popular code element I mean a project (but the idea works also for packages and types) that is massively used by other projects of the program.
It is not a good idea to have concrete types very popular in your code base. This provokes some Zones of Pains in your program, where changing the implementations can potentially affect a large portion of the program. And implementations are known to evolve more often than abstractions.
The main sequence line (dotted) in the above diagram shows the how abstractness and instability should be balanced. A stable component would be positioned on the left. If you check the main sequence you can see that such a component should be very abstract to be near the desirable line – on the other hand, if its degree of abstraction is low, it is positioned in an area that is called the “zone of pain”.
Only the Fondation project is inside the zone of pain , which is normal because it’s very used by the other projects. and contains mostly utility classes which are not abstracts.
TYPE COHESION
The single responsibility principle states that a class should not have more than one reason to change. Such a class is said to be cohesive. A high LCOM value generally pinpoints a poorly cohesive class. There are several LCOM metrics. The LCOM takes its values in the range [0-1]. The LCOMHS (HS stands for Henderson-Sellers) takes its values in the range [0-2]. Note that the LCOMHS metric is often considered as more efficient to detect non-cohesive types. LCOMHS value higher than 1 should be considered alarming.
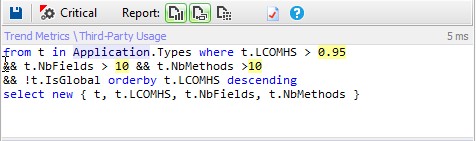
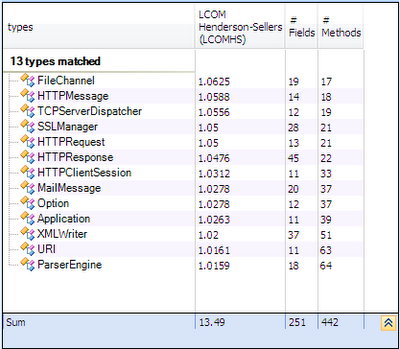
Only 1% of types are considered as no cohesive.
In this post, we’ve offered a brief glimpse into the design of POCO. In upcoming posts, we’ll explore its design and implementation in greater detail to understand why this library stands out as one of the well-implemented open-source C++ libraries.

